|
Optimizing the Ethereal Engine Version 1 EtherealMatter
Prithvish V N,
Brief | Report | Poster
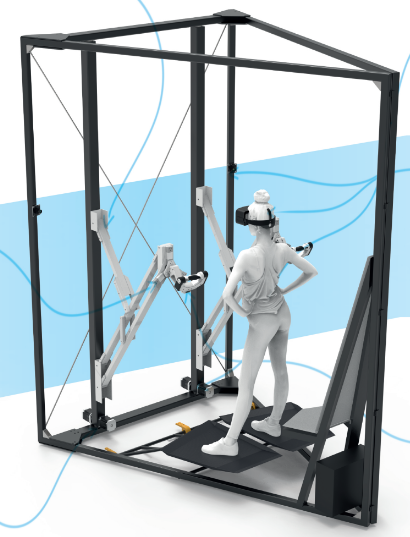
Worldwide obesity has nearly tripled since 1975 and is still growing . More than a quarter of the world’s adult population is physically inactive, which has resulted in poor health systems and negative impacts on well-being . Physical activity has been shown to have significant health benefits for hearts, bodies, and minds, as it prevents noncommunicable diseases, reduces symptoms of depression and anxiety, and improves overall well-being . Still, more than 80% of the world’s adolescent population and 20% of the adult population are not sufficiently physically active . In particular, technological advancements in the gaming industry have led to a larger number of people, including children, spending time on video games rather than engaging in physical exercises. The rising adoption of a sedentary lifestyle increases the risk of non-communicable diseases such as type 2 diabetes and obesity. Interactive fitness products try to fight this increasing problem by introducing technology to the fitness industry market, making workouts safer, more fun, and flexible. This so-called exergaming is considered the most promising product as physical exercises are combined with video games to help people build up their strength and improve their fitness levels. One of the companies involved in this exergaming industry is Ethereal Matter, whose vision is to create "a full-body, intelligent fitness platform enabling immersive virtual-physical interaction, adaptable to the range of humanity who desire the benefits of improved health." To achieve this vision, a prototype called the "Ethereal Engine" was created. In this engine, games can be played by the end-user while working out and even being social with friends and family all over the world through virtual reality (VR). The machine consists of two robot armatures that the user can steer to move in the VR and that can also provide resistance to activate the muscles. However, the prototype still faces many challenges, and since Ethereal Matter is a start-up company with limited engineering resources, this is where we, as an interdisciplinary team of engineers, can contribute.Due to the 10-week time constraint, the team decided to focus on improving the armatures of the existing prototype. The goal of this project is to tackle the challenges related to the armatures and deliver a concept, and when possible a prototype, of an improved product. Through various conversations with the client, it is understood that providing a completely new conceptual iteration would not fulfill the client's expectations. Thus, to provide valuable progress, different areas of improvement are considered and addressed: Human Range of Motion, Virtual Immersion and MoCap, Dead-man grip, Sensor Box, Power management, Industrial design and Manufacturing, Prototyping, and Innovation management. In this project, interdisciplinary knowledge will be utilized and integrated to achieve a product concept. Furthermore, theoretical knowledge will be combined with practical hands-on experience and literature analysis on social, scientific, and ethical issues. Lastlgiy, future scope and a road map are addressed to guarantee the project's continuity. The report gathers all the aforementioned aspects, guiding the reader through the project process.
|

|
Flight control software for a Quadrupel
Prithvish V N,
Brief | Repository | Report
This project aims to build flight control software for the operation of a Quadrupel (QR) drone from scratch. The scope of the project spans from enabling simple joystick-based manual control to implementing automatic motion stabilisation through cascaded P control. The developed software acknowledges constraints on safe states, memory, and power of the QR flight control board (FCB) by implementing several failsafe mechanisms as well as software workarounds for hardware inadequacies. The software was rigorously tested on the physical system and tuned to optimise for inconsistencies between assumptions and hardware performance. The final version of the project was able to achieve the set control goals to a reasonable extent, though further design iterations could have improved the robustness of the system and ironed out the minor flaws that were observed during its operation.
|
|
High-Performance Binary Neural Networks for MNIST Classification: From Software to ASIC
Prithvish V N,
Brief | Repository | Report
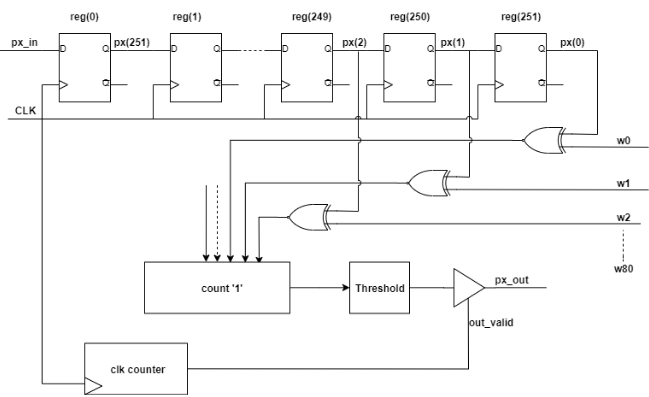
In this project, we explore the design and implementation of a Binary Neural Network (BNN) for image classification tasks, specifically focusing on the MNIST dataset. The motivation behind using BNNs is their potential for significantly reduced computational resources, making them ideal for edge computing and embedded systems. BNNs store weights as binary values (+1 or -1), allowing for faster computations using simple bitwise operations and reduced memory requirements. The robustness of BNNs against adversarial attacks is also highlighted, given their binary nature. We implemented a convolutional neural network in TensorFlow and utilized the Larq library for quantizing the layers. The network architecture comprises a convolutional layer, a max-pooling layer, and a fully connected layer. For the hardware implementation, we translated the trained model into VHDL. The hardware architecture includes modules for convolution, max-pooling, and fully connected layers, each synchronized by an internal clock counter. The ASIC implementation was simulated using GENUS, achieving a substantial speedup compared to software inference on a GPU. The implementation's minimum clock period was 2.79 ns, corresponding to a maximum operating frequency of 358 MHz. The latency and energy consumption of the design were also analyzed, with further optimizations suggested to improve performance.Overall, the BNN hardware implementation demonstrates significant performance improvements, justifying further exploration of architectural enhancements.
|
|
Canny Edge Detector Algorithm acceleration on an FPGA
Prithvish V N,
Brief | Repository | Report
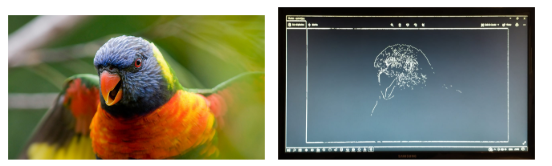
The project covers a successful implementation of Canny edge detection in software as well as in hardware. Software implementation is used as a reference to evaluate the correctness and performance of the design. It can be concluded from the results of the design that the correctness reduces due to limited registers in the FPGA, which does not allow complete partitioning of the buffer in the Hysteresis stage. The performance increases significantly by optimizing the Sobel filter using the CORDIC algorithm, pipelining the operations, using intermediate arrays, and removing false dependencies.
The goal of the project is to analyze the advantages and disadvantages of real-time video streaming applications using FPGA by accelerating Canny edge detection. The main advantage is the speedup of the process. The performance increased significantly compared to the software-implemented Canny edge detection. However, the image is shifted due to buffering of the input pixels. The main disadvantages are the shifted output image and reduction in the correctness of the image.
There are three improvements suggested for future work: partial processing on CPU, dynamic thresholding, and improving Gaussian stage implementation. First, Canny edge detection with other algorithms that rely on edge detection, such as Hough transforms or image segmentation for machine learning, can be partially divided between the processor and the FPGA to reap the full benefits of hardware/software co-design. Second, the two thresholds at the Double-threshold stage can be determined dynamically based on the complexity of the provided image or frame. Finally, after optimizing the Sobel filter implementation using the CORDIC algorithm, it can be seen that the Gaussian block is the most time and area-consuming. This stage can be optimized dynamically based on the complexity of the provided image or frame.
|
|
Low power MIPS Architecture
Prithvish V N,
Brief | Code & Report
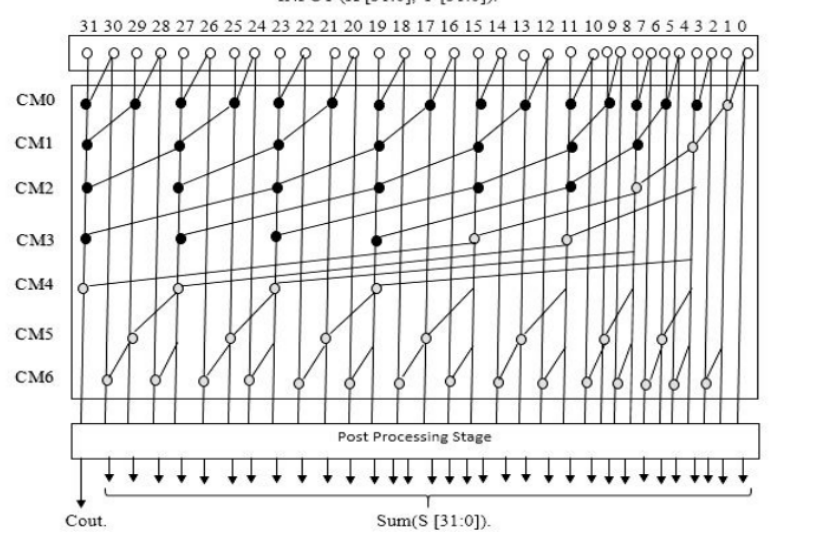
This project aims to lay out the changes made to a simple MIPS architecture processor in order to improve severalperformance metrics of it such as speed, energy use and power consumption, as well as area. For this reportin particular the decreasing energy consumption while maintaining decent performance was considered aboveall. To that end, three major parts of the original processor were modified. Those were the cache hierarchy,the adder module for the alu and also the multiplier unit. In this report through design space exploration thebest cache configuration was found, resulting in about 3.2 Joules saved and 2.8 million cycles less. Finally, afterdoing research, the best options for the other two changes were found. Where after a radix-4 multiplier anda prefix adder were implemented. A final processor capable of running the benchmarks in 4948 million cycleswith only 7.59 Joules was achieved.
|
|
Deep Orchards - Reproducibility project
Prithvish V N,
Brief | Repository & blog
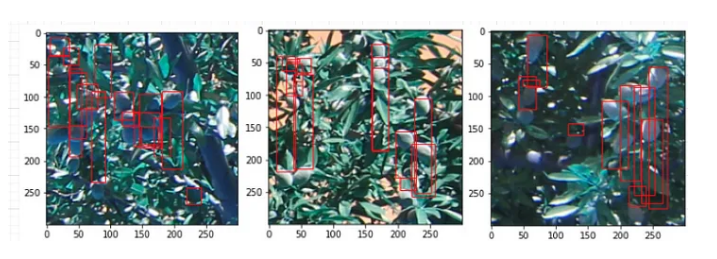
Terms like Deep learning and machine learning have been quite popular these days. There have been several advancements in the field over the last couple of years. Having seen several fields slowly adapting techniques to solve problems via deep learning and machine learning encouraged encouraged us to take up deep learning courses in our Masters. While courses give you a basic understanding on a subject, Projects have always been an interesting way of learning new concepts hence we took up a challenging project to integrate the Deep Orchards dataset with the Faster RCNN network and reproduce the research paper. The work takes you through the very basic steps one should follow if you are a newbie in deep learning.
|

|
Kitchen Cleaning Robot
Prithvish V N,
Brief | Repository
In this project, our robot is taught to clean up a table after a meal. In particular, it needs to be able to pick up cutlery (forks, knives, spoons). For that the robot needs to determine where the cutlery is located and where the handle is. The robot has a basic down-facing camera that it can place on top of the desk to inspect an area of interest. Your task is to design the machine learning method for this perception problem. To simplify the problem, we'll only consider a single type of cutlery (your choice of fork, spoon, or knife) and a single object visible in each camera picture.
|
|
Starliner mission model in mCRL2
Prithvish V N,
Brief | Repository
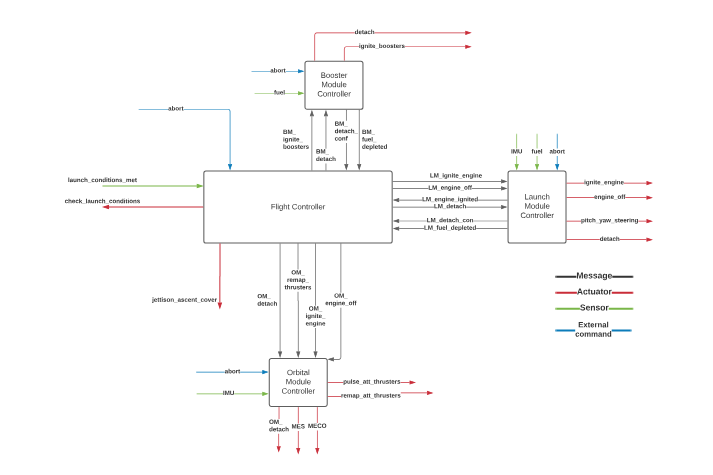
This system validation project will focus solely on the launch segment of the Starliner Mission. The launch starts on the ground and terminates when the Service and Crew Modules (SCM) are detached from the Orbital Module (OM). The main events as listed below will be modelled in mCRL2 using four independent controllers running in parallel. As further described in section 2, these consist of a Flight Controller (FC), Booster Module Controller (BMC), Launch Module Controller (LMC), and Orbital Module Controller (OMC)
|
|
Real time execution of a multiprocessing system - A survey
Prithvish V N,
Brief | Report
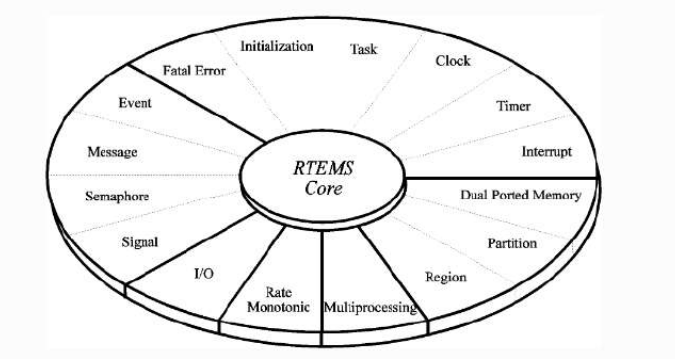
The Real-Time Executive for Multiprocessor Systems or RTEMS is an open source Real Time Operating System (RTOS). RTEMS is widely used in space flight, medical, networking and many more embedded devices. RTEMS currently supports 18 processor architectures and approximately 200 BSPs. which include ARM, PowerPC, Intel, SPARC, RISC-V, MIPS, and more. RTEMS includes several APIs, support for multiple device drivers, multiple file systems, symmetric multiprocessing (SMP), embedded shell, and dynamic loading as well as a high-performance, full-featured IPV4/IPV6 TCP/IP stack from FreeBSD which also provides RTEMS with USB. Apart from this, RTEMS also supports various scheduling framework which makes it ideal choice for many Real time embedded applications. In the layered stack, RTEMS servers as a middle layer between the application layer and the hardware just where device drivers are placed.
|
|
Optimization and Overhead Analysis of Real-Time Systems Using Earliest Deadline First Scheduling
Prithvish V N,
Brief | Report
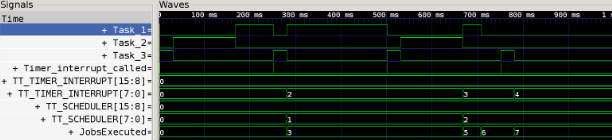
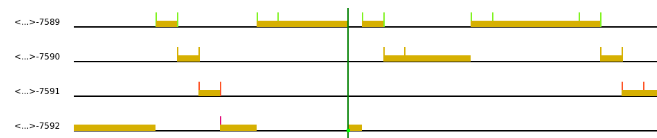
This project explores the calculation and impact of system overhead in real-time systems, with a focus on the implementation of the Earliest Deadline First (EDF) scheduling algorithm. The overhead encompasses context switching, scheduling functions, and timer interrupt handling. Using a timetracker function, we measure and analyze the overhead as a function of the number of tasks, demonstrating an increase in overhead with the number of tasks due to more frequent scheduler and interrupt invocations. The project also examines how task set parameters, such as periods and execution times, influence the total system overhead, revealing that shorter periods result in higher overhead. Detailed implementation of the EDF scheduler is provided, showcasing how it manages task execution based on deadlines. The findings are supported by plots illustrating the correlation between increased task frequency and higher overhead, offering insights into optimizing real-time system performance.
|
|
Comparative Analysis of Real-Time Scheduling Policies: SCHED_FIFO, SCHED_RR, and SCHED_DEADLINE
Prithvish V N,
Brief | Report
The project presents a comparative analysis of real-time scheduling policies SCHED_FIFO, SCHED_RR, and SCHED_DEADLINE, evaluating their performance through a set of periodic tasks with varying priorities and computation times. SCHED_FIFO prioritizes tasks based on arrival times, executing higher-priority tasks first, while SCHED_RR allocates fixed time slices to tasks in a cyclic manner, promoting equitable CPU time distribution at the cost of increased context-switching overhead. SCHED_DEADLINE, utilizing Global Earliest Deadline First (GEDF) and Constant Bandwidth Server (CBS), ensures that tasks meet their deadlines without exceeding their runtime limits. Detailed overhead calculations reveal the impact of scheduler and timer interrupts on system performance, with analyses illustrating how task parameters influence total overhead. The findings, supported by plots of overhead percentages relative to task numbers, highlight the strengths and limitations of each scheduling policy, offering insights for optimizing real-time system performance.
|
|
Compative study and optimized implementation of scheduling and resource binding algorithms in digital system design for different filters
Prithvish V N,
Brief | Repository
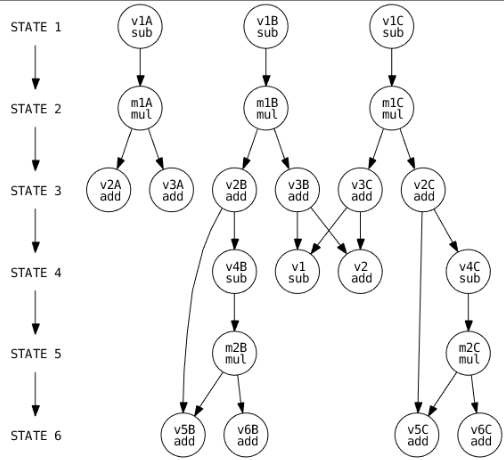
This project presents a comprehensive evaluation of scheduling algorithms in the context of system design, with a particular focus on MATLAB-based simulations. We investigate the performance and trade-offs associated with various scheduling techniques, including As Late As Possible (ALAP), Force Directed Scheduling, and LIST Scheduling. Our analysis emphasizes key metrics such as clock period minimization and resource utilization efficiency.We delve into the extraction of Pareto points to illustrate the inherent trade-offs between critical design parameters. Additionally, we explore the re-timing of circuits, demonstrating its impact on clock period reduction and the corresponding increase in register count. Our findings highlight the necessity of balancing these factors to optimize overall system performance.Precision analysis is conducted to evaluate the influence of coefficient bit precision on circuit behavior. By adjusting the fractional bit count, we enhance precision and observe its effects on design outcomes. The study employs a configuration of 17 total bits with 15 fractional bits for detailed analysis. To validate our theoretical insights, we generate VHDL testbenches and conduct simulations using ModelSim. These simulations confirm the accuracy of our MATLAB testbench outputs and identify timing violations, guiding subsequent design refinements. Our results underscore the efficacy of re-timing in optimizing circuit performance, contingent upon meticulous management of critical paths and resource allocation. This paper provides valuable insights into the comparative performance of scheduling algorithms and the practical implications of design decisions in system design.
|
|
Comparing caching methologies for multiprocessor system- A survey
Prithvish V N,
Brief | Report
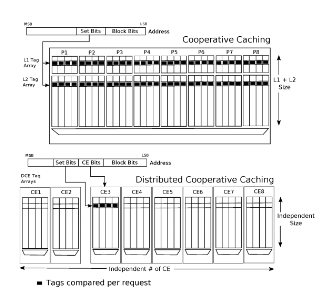
This survey project presents an overview and comparison of three different caching methodologies for Chip Multiprocessor (CMP) systems. We first explore a framework called Cooperative Caching (CC) framework, which provided the groundwork on how to efficiently manage on-chip cache resources. We then present an improvement on the performance of the CC framework for higher number of processes using Distributed Cooperative Caching (DCC) .Finally, we present another methodology, Adaptive Set-Granular Cooperative Caching (ASCC) [3], which also improves upon CC by adopting an efficient cache spilling policy for the onchip caches. We compare the mentioned methodologies using various common evaluation metrics – percentage of performance improvement, number of off-chip misses per transaction and network latency – measured while running workloads from common SPEC benchmarks. We also show which of the methods perform the best in a given scenario using qualitative metrics. We end the review mentioning our reflections on each of the three proposals.
|
|
Optimizing the VLIW archiecture for benchmarks on a simulating platform
Prithvish V N,
Brief | Report
This project presents our analysis of the benchmarks - matrix multiplication and 7x7 convolution. We consider both of the application to be of scientific domain and thus our focus is primarily on optimizing the performance as compared to the utilization of resources. We show our process of finding the optimum VEX architecture and then explain the reason behind the optimal configuration.
|
|
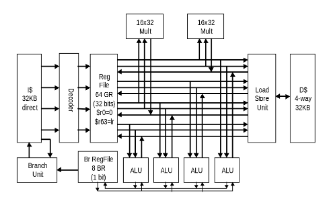
Optimizing the VLIW and VEX architecture on an FPGA
Prithvish V N,
Brief | Report
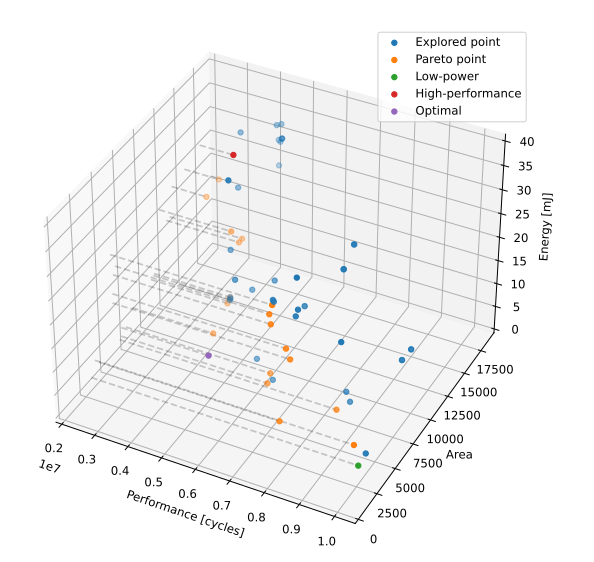
This project presents our analysis of the matrix multiplication, 7x7 convolution, jpeg and greyscale benchmarks on an actual physical FPGA using the VLIW configuration. We present our configurations for three different domains, namely low-power embedded systems, high-performance scientific systems and an efficient compromise between performance, energy and area. We also present the results of our design space exploration and discuss the various hardware and software configurations used.
|
|
Discrete Time State Space Model Optimization for a traffic network - Non linear optimization
Prithvish V N,
Brief | Code & blog
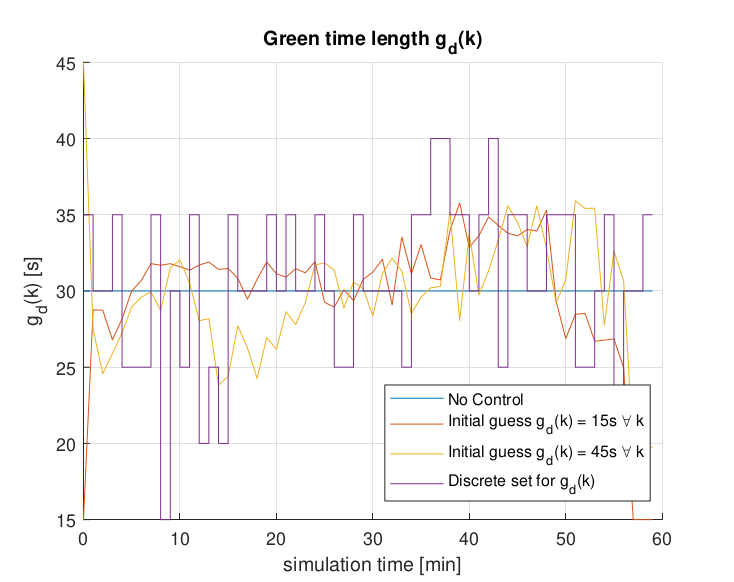
The project focuses on optimizing an urban traffic network using nonlinear programming. It presents a discrete-time state-space model for the network, formulates and solves the optimization problem, and analyzes the results, particularly in terms of queue lengths and the number of vehicles under different scenarios. Key findings include the identification of output link capacity as a limiting factor and the observation that the total time spent in the system (TTS) remains consistent across different initial guesses for green time lengths and the no-control case. The analysis demonstrates that the optimization algorithm effectively minimizes TTS by determining optimal green time lengths for traffic signals.
|
|
Optimization of a cooling system - Linear and quadrating programming
Prithvish V N,
Brief | Report
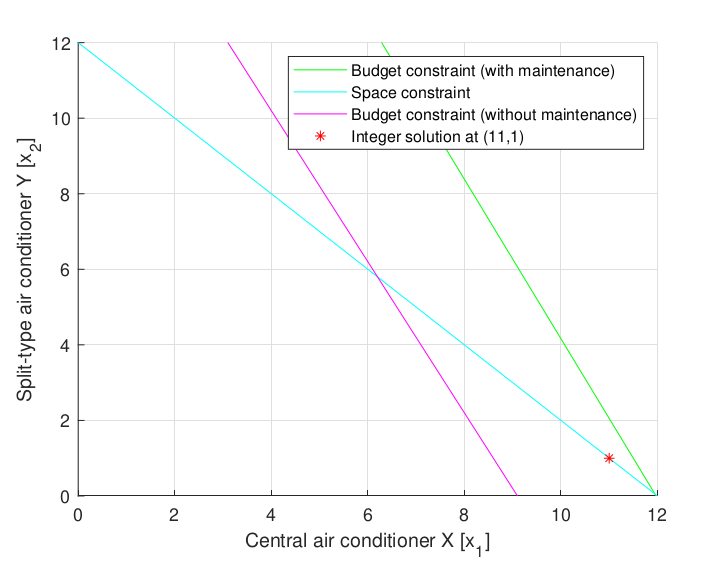
The project focuses on optimizing various optimization problems within systems and control. The project covers the formulation of constraints and solutions, including integer solutions for air conditioning units to maximize power under budget and space constraints. The project also delves into discrete models, parameter identification, and converting problems into forms suitable for quadratic programming using MATLAB. The overarching goal is to minimize the quadratic cost function while adhering to thermal comfort bounds and energy input limits. The project emphasizes the application of these optimization techniques in practical engineering scenarios.
|
|
Acceleration with SSE/AVX/AVX2 OpenMP, OpenCL
Prithvish V N,
Brief | Report
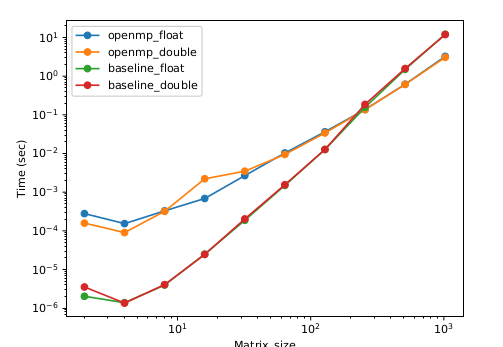
This project is focused on the analysis of various computational techniques by implementing matrix multiplication. Our goal is to accelerate and optimize both single-precision and double precision matrix multiplication by the use of Intel SSE/AVX/AVX2, OpenMP and OpenCL on multi-core processor systems. We state our observations of the performance of each implementation and analyze why and when which imple-mentation works better. We benchmarked the implementations with that of a native matrix multiplication wherein no optimizations have been applied. We then conclude with a brief discussion of the current trend on how each of these paradigms are being used currently.
|
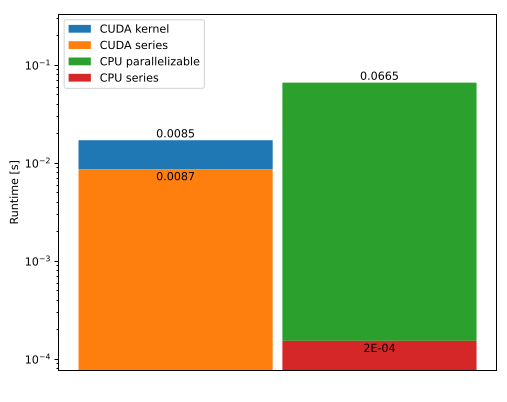
|
Accelerating image processing algorithms with CUDA
Prithvish V N,
Brief | Report
This report is focused on the implementation and analysis of the optimization of a basic image processing algorithm using NVIDIA CUDA toolkit. CUDA is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, it is possible to dramatically speed up computing applications by harnessing the power of GPUs. In our case, the image processing algorithm consists of 4 stages namely histogram calculation, contrast enhancement, ripple effect and Gaussian blurring. We provide the optimized algorithm and compare the performance of the with that of the serial execution.
|

|
Acceleration of a Convolution Neural Network
Prithvish V N,
Brief | Report
This report is focused on the implementation and analysis of the optimization of a basic CNN classification algorithm. CUDA is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, it is possible to dramatically speed up computing applications by harnessing the power of GPUs. We provide the optimized algorithm and com-pare the performance of the same with that of the base- line serial implementation. We also try to use various other paradigms whenever possible to get the maxi-mum performance out of the algorithm.
|

|
MindSwitch
Prithvish V N,
Brief | Video | Repository Poster Report
Human brain is like the central processing system. It is responsible for almost the entire activities, feel and responses of a human. Brain Computer Interface (BCI) [x] is playing a important role in making the lives of severely disabled people better and self-manageable. BCI provides an effective means for communicating or to control or operate several devices, to the physically challenged. During the last decade many BCI enabled devices like Neural prosthesis, robotic platform[x] and general tools for human-machine interaction have been developed in labs. Electroencephalography is a means for measuring the electrical activity in brain. The EEG signal is measured by placing one to several electrodes on the scalp in various locations based on the kind of response one wants to measure. These electrodes record the electrical activity generated by the brain’s nerve cells. The summed up electrical activity of numerous neurons is transmitted through the electrodes interfaced by a conducting gel and using a data acquisition module, are recorded and stored. This facilitates to explore the functioning of brain and its responses to various real world external stimuli like light, colours, sound, taste and touch. The recorded electrical activity consists of impulses of different frequencies and is processed in particular regions of brain called lobes. Four different lobes corresponding to various tasks - Frontal, Parietal, Temporal, Occipital. The electrical activity of brain which occurs very quickly due to which a system with very high time resolution is needed so as to not miss any electrical activity that might occur at an instant. Since EEG is the summed up electrical activity of the brain it’s time resolution is very high. Secondly, it is easy for researchers and safe for the subjects, to record the activity as it does not involve invasive procedure. Finally the portability of the sensors and equipment combined with the low cost when compared to other devices used like fMRI, MRI and CT makes it more preferred method when compared to fMRI, MRI and CT scan. The drawback of spatial resolution in EEG is compensated by more advance techniques that have been evolved in analyzing EEG that helps in better estimation of signal’s source.The advent of wearable sensors, along with compressed sensing of EEG signals, electroencephalography will facilitate more dynamic study and analysis of brain’s functioning and responses, in a subject’s natural environment. This will give rise to more portable and dynamic BCI applications. From the pre-processed EEG signals segments, set of features can be extracted to represent each of these segments. The features can be either statistical in nature, frequency domain features or entropy based features. With the help of these features and a robust classification algorithm, a good platform for several BCI based application for physically challenged can be developed. Over the last few years many BCI applications were developed using slow cortical potentials, event related potentials, P300 and visually evoked potentials.
|
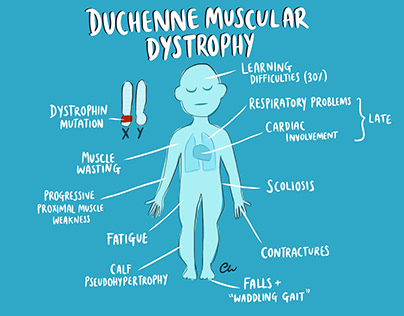
|
DMD4DMD
Prithvish V N ,
Brief | Paper |Video
Duchenne Muscular Dystrophy is one of the rare diseases for which there has been no cure till date. This disease affects 1 in 3500 male children and the life expectancy of the patient is about 15-20 years. Our device, DMD4DMD, helps practitioners and researchers monitor and analyze the progressiveness of disease. The design aims at minimizing the hardware such that the device is light in weight, wireless and wearable. One of the main significance of this device is to create a global repository where any physician around the globe can access data and analyze the condition of patients. Our device expands the area of research of a rare disease whose symptoms are hard to diagnose at early stage.
|

|
Team Technocrats - Badminton Playing Robots (ROBOCON 2015 ASIA PACIFIC)
Prithvish V N,
Brief | Repository | Video | Website
ROBOCON is an Asia-Pacific robotics competition held every year with different problem statements. The problem statements are carefully curated to encourage design innovations in the field of robotics. The problem statement for the year 2015 was to make 2 robots that will play a doubles badminton match with the other team’s robots. The choice of fully automated vs manual robots was provided by the organisers.
|
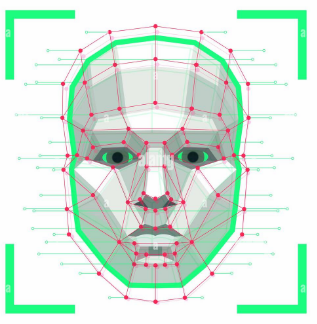
|
Multi-Model Person Identification System
Prithvish V N,
Brief | Repository | Report
In this project, we present an audio-visual feature-level fusion for person identification system using a combination of acoustic features, fingerprint images and 2D face images. Person identification is of paramount importance in security, surveillance, human computer interfaces, and smart spaces. There are numerous instances where a single feature, however, sometimes fails to be exact enough for identification. Also, another disadvantage of using only one feature is that the chosen feature is not always readable. Thus, a multimodal approach using three different modalities - face, voice and fingerprint - takes care of all such instances and achieves greater accuracy than single feature systems. The speaker verification is done by extracting Mel Frequency Cepstral Coefficients followed by Support Vector Machine. The facial recognition is done using Local Binary Pattern histogram face recognizer after performing Harr cascade for face detection. The fingerprint verification is done using binarization on a grayscale image, followed by skeletonization and then the minutiae points are found using Harris corner detector. All the three above approaches are implemented on hardware using BeagleBone Black along with audio microphone and USB cameras as sensory modules. The various sensory modalities, speech, fingerprint and faces, are processed both individually and jointly and it has been observed that the performance of the multimodal approach results in improved performance in the identification of the participants. Our system achieves around 90% recognition and verification rates on natural real-time input with 10 registered clients.
|
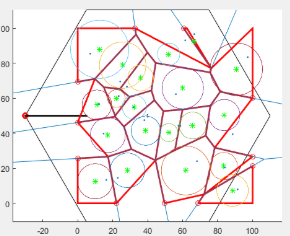
|
Simulating handoffs in hetrogenous mobile networks and improving the placement of micro cells through geometrical approaches
Prithvish V N,
Brief | Repository | Report
Effective network planning is essential to cope with the increasing number of mobile broadband data subscribers and bandwidth-intensive services competing for limited radio resources. Operators have met this challenge by increasing capacity with new radio spectrum,adding multi-antenna techniques and implementing more efficient modulation and codingschemes. However, these measures alone are insufficient in the most crowded environmentsand at cell edges where performance can significantly degrade. Operators are also addingsmall cells and tightly-integrating these with their macro networks to spread traffic loads,widely maintain performance and service quality while reusing spectrum most efficiently.One way to expand an existing macro-network, while maintaining it as a homogeneousnetwork, is to “densify” it by adding more sectors per eNB or deploying more macro-eNBs.However, reducing the site-to-site distance in the macro-network can only be pursued to acertain extent because finding new macro-sites becomes increasingly difficult and can beexpensive, especially in city centres. An alternative is to introduce small cells through theaddition of low-power base stations (eNBs, HeNBs or Relay Nodes (RNs)) or Remote RadioHeads (RRH) to existing macro-eNBs. Site acquisition is easier and cheaper with thisequipment which is also correspondingly smaller. Small cells are primarily added to increasecapacity in hot spots with high user demand and to fill in areas not covered by the macronetwork – both outdoors and indoors. They also improve network performance and servicequality by offloading from the large macro-cells. Further the authors propose and solve theissues of HETNETS in LTE Networks where Small cells are placed closed to each other andrandomly scattered. In this paper proposal, has been made of a unique effective solution tosolve such problems. we shall be using geometrical partitioning and combining techniques toincrease density over the network and solve the issue of randomly placed cells and furtherapply game theoretic approaches to get efficient outputs over user mobile handoff
|
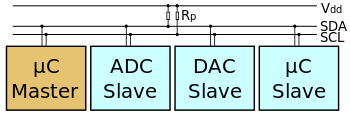
|
Study of I2C communicaiton protocol using MSP430 and Beagle Bone Black
Prithvish V N,
Brief | Report
I²C (Inter-Integrated Circuit), pronounced I-squared-C, is a multi-master, multi-slave single-ended, serial computer bus invented by Philips Semiconductor (now NXP Semiconductors). It is typically used for attaching lower-speed peripheral ICs to processors and microcontrollers in short-distance, intra-board communication. Alternatively, I²C is spelled I2C (pronounced I-two-C) or IIC (pronounced I-I-C). BBB, MSP430 and MPU-6050 having the same operating voltage have been selected as the test and study purpose. In our test BBB is configured as the Master and MPU and MSP being the slaves. Register for MSP430 I2c communication and I2Ctools for BBB will be studied and CCS and Putty will be the Software tools used. The Coding on BBB is done in C. Various modes of I2C were tested and MPU was studied via the help of datasheet. The Acceleration values on MPU and temperature values on MSP was acquired on BBB and displayed.
|
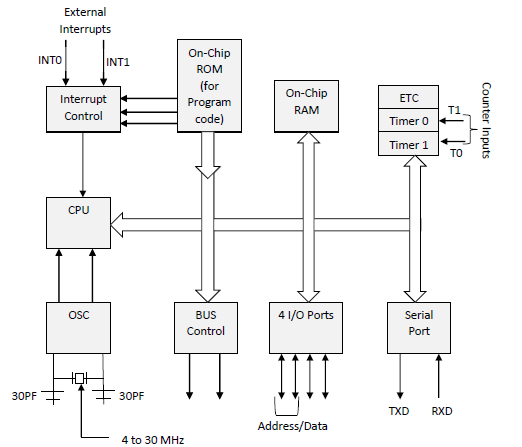
|
Detailed Study of the 8051 microcontroller
Prithvish V N,
Brief | Repository
The project details several aspects of the 8051 microcontroller. It covers the principles of asynchronous start-stop signaling and various communication modes such as UART and USART. It details the usage and configuration of the SCON register for serial communication, including important bits like SM2, REN, TB8, and RB8. The report explains baud rate calculations, provides assembly programs for LCD initialization, UART communication, and interrupt handling, and discusses the practical use of DACs to convert digital data to analog signals. It includes hardware and software tools like Keil µVision 4 and Proteus, and concludes with an analysis of interrupts, memory access efficiency, and practical waveform generation using the 8051.
|
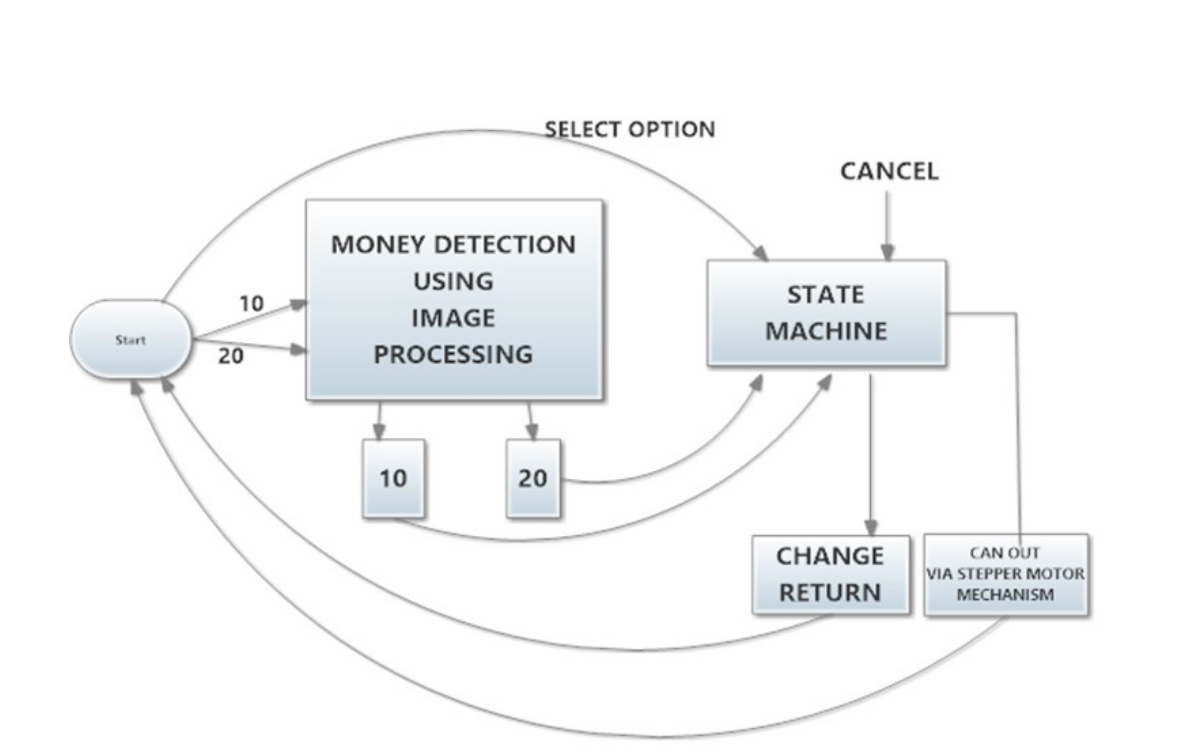
|
Vending Machine
Prithvish V N,
Brief | Report
The project is a replication of vending machines used in Metro localities such as Delhi, Mumbai, Bangalore and other cities abroad. Vending machine is an automated machine that dispenses products in exchange of money that is put into the system. In other words it’s a money operated automated machine for selling merchandise. The task comprises of three stages –finite state machine, followed by sensing hardware and then finally product dispensing mechanism. The project is majorly based on the finite state machine to maneuver the system. The system senses two currency notes (Rs.10 and Rs.20) using SIFT algorithm. The system is efficient in dispensing products more like wafers and chocolates. As per the design the machine will dispense a product only for amount exactly Rs.30. The machine additionally consists of a cancelling mechanism which cancels the order and returns the amount back to the customer.
|
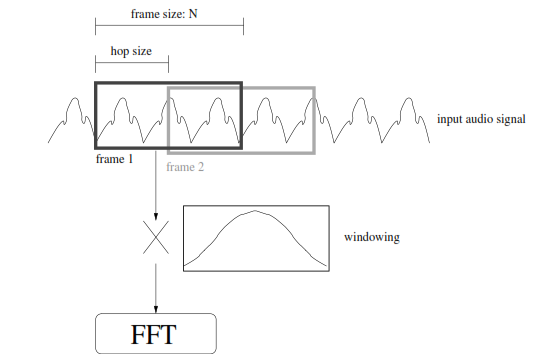
|
Voice conversion
Prithvish V N,
Brief | Repository | Video
Speech processing is currently a key focus for many researchers in the area of DSP. In this project, we focus on the topic of voice conversion, which involves producing the words from one person (the “source speaker”) in the voice of another person (the “target speaker”). We can do this using DSP because every person’s distinct vocal qualities are essentially caused by their vocal tract, which forms a transfer function between the input excitation and the output signal that we hear. We can isolate this transfer function through methods such as cepstral analysis and linear prediction coding, which we describe in detail. The second major identifier between different speakers is the pitch range of their words. We can change the pitch through methods such as the PSOLA, which we also describe. The vocal tract transfer function and pitch range are different for different sounds. Thus, in synthesizing a phrase, we must first break the signal into smaller segments and analyse each individually. Our windowing algorithm divides the signal based on breaks between different syllables and words. We then use functions from the Praat program to perform the analysis and synthesis. Voice conversion has numerous applications, such as the areas of foreign language training and movie dubbing. It is closely related to the process of speech synthesis, which usually refers to converting text into spoken language, and has many applications, especially relating to assistance for the blind and deaf. Other areas in speech processing, such as speaker verification, have applications in security. All of these different types of speech signal processing involve related methods that we investigated through this project, especially cepstral analysis, linear prediction coding, and the PSOLA method.
|
|
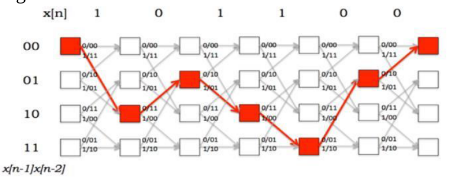
Channel encoding and viterbi decoding on an FPGA
Prithvish V N,
Brief | Repository | Report
This project implements convolutional encoding and decoding using Viterbi algorithm on FPGA (Field Programmable Gate Array). These are popular techniques for channel encoding and decoding. The purpose of channel encoding is to find codes which transmit quickly, contain many valid code words and can correct or at least detect many errors. Channel encoding adds extra data bits (redundancy) to make the transmissio nof data more robust to disturbances present on the transmission channel. Channel decoder attempts to reconstruct the original information sequence from the knowledge of the channel encoding algorithm. Convolutional coding is a type of error correcting codes that generates parity symbols via the sliding application of a Boolean polynomial function to a data stream. Viterbi algorithm aims at finding the mostlikely transmitted message sequence minimizing the BER. Though it is resource consuming but it does themaximum likelihood decoding. It can be a hard decision decoding (using Hamming distance) or a softdecision decoding (using Euclidean distance). These are the techniques commonly used in popular wirelessstandards and satellite communication. This technique is used in various space missions such as marspathfinder, mars exploration rover, cassini probe to Saturn.In the project, a convolutional code with code rate ½ and constraint length 3 is implemented on FPGA(SPARTAN 3E) and the same is decoded using hard decision Viterbi decoder
|

|
Gesture based locking system
Prithvish V N,
Brief | Report
This project aims to design a revolutionary security system that shall change the present day scenario of opening door locks. A mere gesture of your hand shall unlock the door on which the system is installed. The basic prototype will consist of a small cubical box with laser and LDR array. When the proper Finger gesture is produced in the box, a comparison is made based on a previous pattern recorded. A Stack and polling based concept of the microcontroller/microprocessor will come into picture while interfacing the Laser-LDR system. On circumstantial failure of the above Sub-System after a particular amount of trials, the locking system starts its own access point network through which the owner can connect via his phone. Further a custom made app will be needed to unlock the lock. In this process the lock system will start its own server and the owner’s phone shall act as client. On the door opening request of the client the server will open and close the door when properly authenticated by the correct password. The level of security in such a system is doubled in the second subsystem with a 2 level authentication by the WEP encryption based WIFI security and the App Passkey security
|
|
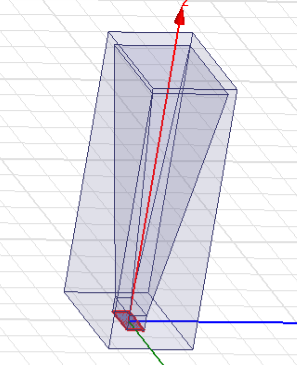
Design for a horn Antenna
Prithvish V N,
Brief | Report
Horn antennas are extremely popular in the microwave region. An aperture antenna contains some sort of opening through which electromagnetic waves are transmitted or received. One of the examples of aperture antenna is horns. The analysis of aperture antennas is typically quite different than the analysis of wire antennas. So in this project, the team decided to simulate a pyramidal horn antenna in HFSS 13, since pyramidal antennas are widely used for communication purpose. The resonating frequency was fixed at 10GHz and the 3D Polar plot, rectangular plot for impedance of horn antenna, Gain v/s Frequency plot, directivity plot and antenna parameters were obtained for a practical design of pyramidal horn antenna.
|
|
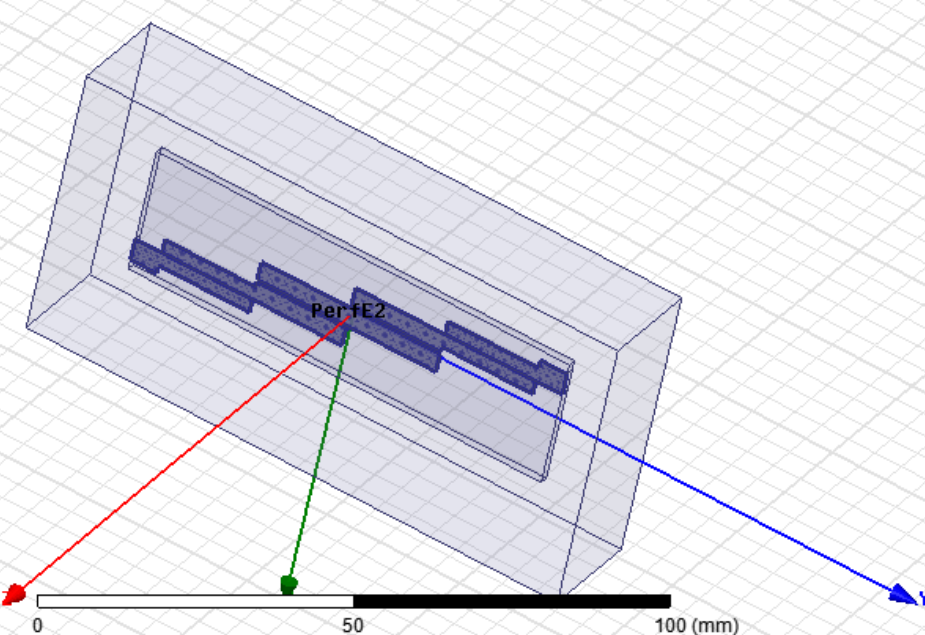
Band-pass filter design for microwave frequency using HFSS
Prithvish V N,
Brief | Report
At the receiver side there is a requirement to filter out the noises and pass only the desired signal frequency for processing. Hence, a Band Pass Filter (BPF) is required for the same. In the present project the designing of a compact microwave parallel edge coupled line BPF has been discussed and implemented. The BPF consists of a 4-parallel coupled line pairs designed for a Chebyshev response at a center frequency of 2.48 GHz with a fractional bandwidth of 10%. The filter has been implemented using FR4 substrate of dielectric constant 4.2. The physical parameters of the parallel coupled line filter sections have been simulated using the HFSS software to provide the closest values of the band pass filter prototype values.
|
